
What is a System
Before we dive into the details of building a distributed, scalable system, we should answer the question of what is a system.
A System is a set of interacting or interdependent components forming a complex whole.
Let’s stop there for a moment ✋ and dive into what this definition means, what interacting and interconnected mean and then understand how it applies to computing systems.
For example, the city or the town you live in or any other city you have in mind. You will find that a city has a set of interacting or interdependent components forming a complex whole.
A city is made of, but not limited to:
- Transportation Infrastructure - roads, bridges, tunnels, etc.
- Utilities and Services - water, electricity, gas, etc.
- Housing and Shelter - houses, apartments, etc.
- Public Spaces - parks, squares, etc.
- Education Facilities - schools, universities, etc.
- Healthcare Facilities - hospitals, clinics, etc.
- Economic Zones - business districts, industrial zones, etc.
- Safety and Security - police, fire department, etc.
- Communication and Technology - internet, mobile networks, etc.
- Governance and Administration - city hall, courts, etc.
Each of these components is interacting, sometimes interconnected, other times independent, operating in parallel to form a city. Each component has its defined scope and responsibility. The police will not perform surgery on a patient, and the doctor will not arrest a criminal. If this were to happen, the system would be broken, and the city will not function properly.
On the other hand, if the Administration organises an event, the police will be there to ensure the safety and security of the people attending the event, and the ambulance will be there to provide medical assistance if needed. While a city analogy may not entirely apply to a computer system, it explains the concept of a system and its components.
Keeping system components independent and focused on their scope and responsibility is a key factor in a healthy system.
A computing system is made of, but not limited to:
- Hardware - CPU, RAM, Storage, etc.
- Software - Operating System, Applications, etc.
- Network - Routers, Switches, Cables, etc.
- Data - Databases, Files, etc.
- Services - Web Servers, Application Servers, etc.
- Security - Firewalls, Intrusion Detection Systems, etc.
- Monitoring - Metrics, Logs, etc.
- Automation - Scripts, Configuration Management, etc.
- Deployment - Continuous Integration, Continuous Delivery, etc.
- Cloud - Infrastructure as a Service, Platform as a Service, etc.
Each component is interacting, sometimes interconnected, other times independent, operating in parallel. Each component has its defined scope and responsibility. When diving into the details of each component, we will see that they are made of smaller components, and the same applies to those smaller components .
Why do we need Systems?
The most important fact to mention about a system is the why - Why this large-scale system exists in the first place? The answer may sound ridiculously obvious, yet again, it is essential to touch to the core.
Traditionally, cities have been established and grown with the aim of serving the needs of their inhabitants. They often provide essential services and foster communal growth, aiming to make lives better, happier, and more prosperous.
Similarly, a computer system ultimately exists to serve users. It is vital to remember that you will not build a system in isolation and there are always people who will use it in one way or another.
A system is designed to achieve a specific goal. If it fails to achieve that goal, it may need to be redesigned or replaced.
Designing a system starts with understanding the purpose of the system, the reason it exists, setting the expectations and defining the success criteria.
That’s being said the purpose of a system can change over time. For example, a city might be built to serve as a transportation hub, but it might later become a major economic center. The purpose of a system should be defined early on in the design process, but it should also be flexible enough to adapt to changes over time.
Why Systems need to Scale?
Imagine our city analogy again. Can it handle double, triple, or even five times its current population? If it can, that’s a scalable city (or system). It can adapt and expand to accommodate growing demands effectively.
The same applies to computer systems. While not every system requires scalability, it’s crucial to understand the challenges that arise when scaling becomes necessary. Ultimately, a successful system, or its components, will need to scale in one form or another.
As a system scales, many new challenges come to the forefront. However, before we go into the nitty-gritty details, let’s look at the fundamental issues that emerge when scaling a system.
Understanding the problem is the first step towards finding a solution.
For example, A small town has a police station, hospital, school, fire department, and other facilities catering to its current population. As the town grows and its population increases, new scenarios and challenges arise.
The increased Load
The main challage that the town would face is to handle the increased load, demands on essential services such as the police station, hospital, school, and fire department surge.
There are two approaches to solve this problem:
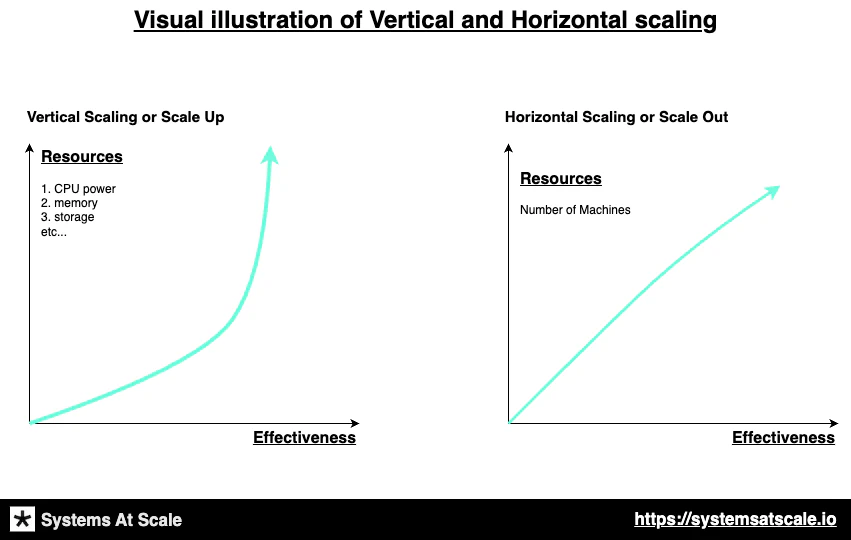
Vertical Scaling or Scale Up
The first approach is known as vertical scaling or scale up
Vertical Scaling or Scaling up refers to adding more resources to a single system component.
Picture it like this: Expanding the current police station, hospital, and school by hiring more personnel, procuring additional equipment, and increasing the physical size of these facilities. However, there’s a crucial point when the police station, hospital, and school can’t grow any larger. It would be physically impossible and economically not viable. Ignoring these constraints, even if feasible, would result in the population having to travel longer distances, longer queueing to reach these essential facilities.
Vertical Scaling is limited by the physical and economic limitations of the system.
In computer systems, vertical scaling is a way to accommodate growth without fundamentally changing the architecture, throwing more CPU or RAM into the existing infrastructure. However, there are limitations to vertical scaling, as the physical constraints of the server bound the capacity growth and may eventually become cost-prohibitive.
As shown in the diagram, scaling vertically to a certain point may be effective, after which the effectiveness gain starts to fade no matter how many resources you add to the system.
This approach can be no longer feasible or economical, leading to exploring alternative strategies like horizontal scaling.
Horizontal Scaling or Scale Out
Let’s return to our city analogy. Instead of making larger the existing police station, hospital, and school, consider the option to construct more of these facilities or, simply put - adding more components to the system.
Horizontal Scaling or Scaling out refers to adding more instances of the same component to a system to handle increased load.
Theoretically, there is no limit to how many police stations, hospitals, and schools you can build. That being said, we have distributed independent components that can scale up independently.
Now we can refer to this as a distributed system as its components are distributed across the system but working together to form a complex whole.
However, its effectiveness is limited by the system’s ability to distribute this load evenly. Think of it like adding more lanes to a highway; while it can handle more cars, it’s only effective if the traffic spreads out across all lanes.
In computer systems, horizontal scaling is a way to accommodate growth by adding more components to the system instead of increasing the capacity of existing ones.
This approach is more comprehensive than the physical constraints of a single server. It can scale to meet the demands of the system and does not have a single point of failure. However, it’s important to note that horizontal scaling introduces new challenges we must address.
Benefits of horizontal scaling
- Improved performance: Horizontal scaling can improve the performance of a system by distributing the load across multiple nodes. This can help to reduce latency and improve response times.
- Increased reliability: Horizontal scaling can increase the reliability of a system by providing redundancy. If one node fails, the other nodes can continue to operate.
- Scalability: Horizontal scaling can make a system scalable, meaning that it can be easily expanded to handle more traffic or data.
Drawbacks of horizontal scaling
- Increased complexity: Horizontal scaling can make a system more complex to manage. This is because there are more components to monitor and troubleshoot.
- New challenges: Horizontal scaling can introduce new challenges, such as data consistency and security.
- Management: Horizontal scaling can make it more difficult to manage a system, as there are more nodes to manage.
- Latency: Adding more nodes to a system can increase the latency, or the time it takes for a request to be processed.
Different ways to implement horizontal scaling
- Load balancing: Load balancing distributes the load across multiple nodes. This can be done using hardware load balancers or software load balancers.
- Sharding: Sharding divides the data in a system across multiple nodes. This can help to improve performance and scalability.
- Replication: Replication creates copies of the data in a system. This can help to improve reliability.
Challenges of Horizontal Scaling
Let’s look at some of the most common challenges when scaling a system horizontally.
Discoverability and Communication
So we now have multiple instances of the same component, for example, several police stations. How do we know
- which police station is responsible for which area?
- How do we know which police station is available and which is not?
- How do we know which police station is the closest to us?
People living in the city must know which police station is responsible for their area and how to reach it. This means we need to have a way to discover the police stations and communicate with them with some service discovery or catalogue.
Horizontally scalable systems rely on discoverability and communication for their proper use.
In the context of computer systems, we need to have a way to discover the nodes or machines and communicate with them.
Distribution of Load
Even though we have multiple police stations, hospitals and schools, it does not automatically mean that the load will be distributed evenly.
For example, if we have ten police stations and 9 of them are in the suburbs and one is in the centre, the police station in the centre will be overloaded, and the nine police stations in the suburbs will be underloaded.
In a horizontally scalable system, you need to have a way to distribute the load evenly so that all components are utilized equally.
In the context of computer systems, we need to have a way to distribute the load evenly across all nodes or machines using load balancers .
Data Consistency and Persistence
Data is one of the central components of any system, and the ability to store and retrieve data is crucial. Even more so in a distributed system since the distributed components need access to the same data.
This time Let’s take the example of the hospitals in a city. How do we ensure the data is available across all hospitals if we have multiple hospitals? For example, When a patient completes registration at one hospital:
- Do we ensure the immediate availability of the patient’s data in all other hospitals? In other words, can a patient promptly visit another hospital where the attending doctor can readily access their complete medical history?
- Alternatively, do we ensure that the patient’s data eventually becomes available in other hospitals as they transition to different areas?
Typically, we can categorize data consistency as either strongly consistent or eventually consistent in horizontally distributed systems. The choice between these modes dictates how information is synchronized across distributed components. Maintaining a balance between immediate accuracy and accommodating distributed operations lies at the heart of data management strategies within horizontally scalable systems.
Data in distributed systems demands precise management for scalability, balancing between eventual consistency and strong consistency.
There are many data persistence technologies available like SQL or NoSQL databases, and each has its own advantages and disadvantages.
Latency
Latency in the context of distributed systems refers to the time delay or the period it takes for a request or data to travel from its source to its destination. It’s a crucial metric that directly influences the responsiveness and efficiency of a system. Lower latency indicates quicker data transfer and better user experiences, while higher latency can result in delays and reduced performance.
As you add more components and distribute the load, you need to ensure that the latency is kept to a minimum since the data needs to travel between the components.
Picture a scenario where you dial 999 (the firefighting station in the UK) due to a fire emergency at your residence. In this context, system latency refers to the time firefighters reach your location. If the fire station is far away, the latency will be high; if the fire station is nearby, the latency will be low.
To reduce latency, it’s beneficial to place components closer together. For instance, in digital systems, utilizing data centers located closer to the primary user base or adopting content delivery networks (CDNs) can significantly decrease the time it takes for data to travel, thus enhancing user experience.
Place components closer together to reduce latency.
Throughput
Throughput refers to the volume of tasks, transactions, or data a system can successfully process within a specified time frame. It represents the system’s capacity to manage and execute operations efficiently, with higher throughput indicating a greater capability to handle concurrent tasks and data flows.
Imagine the scenario of commuting to work in a bustling city. System throughput, in this context, refers to the capacity of the city to facilitate the movement of people to their workplaces within a specific time frame. If the city boasts an extensive network of roads and efficient public transportation systems, the throughput will be high.
To boost system throughput and accommodate higher volumes of interactions:
Increase the number of components to increase throughput.
Redundancy and Reliability
Redundancy involves duplicating critical components or resources within horizontally scaled distributed systems, offering backup options in case of failures. Redundancy enhances reliability , ensuring that the system can continue functioning even when specific components malfunction or experience downtime.
Imagine you’re on your way to work on the train. Suddenly, the train comes to a halt due to technical failures. Now, consider a crucial detail: Can you take an alternative train or bus to continue your commute and get to work? If there is, it’s a sign that the system’s got your back – a backup plan in place.
Make components in a system redundant to increase reliability.
Summary
Building and scaling systems, much like urban planning for growing cities, come with challenges and considerations that require careful forethought. The city analogy may not perfectly capture every system design and scaling nuance. Still, it offers a relatable frame of reference. Let’s summarize what we’ve learned:
-
System Definition: A system consists of interdependent components that form a complex whole. Cities and computer systems serve their users and have purposes for their existence.
-
Need for Scaling: As demands increase, cities and computer systems need to grow. Scaling is an adaptation to accommodate the increased load.
-
Vertical Scaling: Think of this as expanding existing facilities in a city. This would add more resources to an existing setup for computer systems.
-
Horizontal Scaling: Analogous to building more facilities in different parts of a city. In tech, this means adding more nodes or components to the
Challenges of Horizontal Scaling:
- Discoverability and Communication: Ensuring components can find and interact with each other effectively.
- Distribution of Load: Equitably distributing tasks and responsibilities across all nodes.
- Data Consistency and Persistence: Ensuring data is consistently available across all nodes.
- Latency: Minimizing delays in tasks or data transfer.
- Throughput: Maximizing the number of tasks or data processed in a specific timeframe.
- Redundancy and Reliability: Building backup systems or nodes to ensure continuous function despite potential failures.